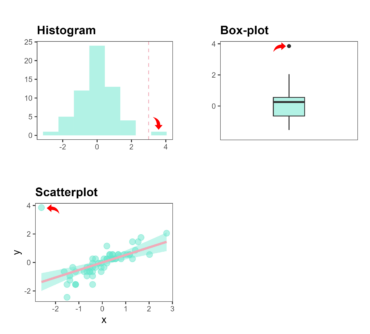
Typical outlier charts
The charts presented below are very practical in data exploration process and show three methods of detecting outliers
So, what can we do to improve the quality of our data, and consequently get more reliable statistical analysis results?
Detection of outliers and what next?
One of the most commonly used method in data exploration step is removing outliers and replacing them by mean or median value. Good information is that you can do that „trick” with only an Excel at your disposal.
Certainly more advanced (if not the most) statistical method of data imputation is provided by `missForest` R package. This method is based on Random Forest algorithm, which impute not only continuous data, but also these categorical ones. It works on complex data, based on the entire dataset, takes into account nonlinear relations between variables and their interactions. This procedure is very useful and “safe” in data exploration phase.
*It is assumed that number of `missings` should be less than 5%.
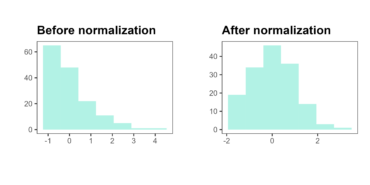
And the last one method - used when variable doesn’t follow a normal distribution is `normalization` provided by `bestNormalize` R package. Normal distribution is required when we use parametric statistical analysis (e.g. regression analysis, anova, t-test). This statistical assumption is not critical, but sometimes is easy to be established, and improves estimates of statistical significance.
The chart presented below shows how normalization works.